🧭 There’s a narrative I keep hearing since Mythos: “AI is about to be so advanced that it can overcome our great cybersecurity defenses.”
That framing assumes our defenses are great.
They’re not.
Mythos found a 27-year-old bug in OpenBSD — a system famous for its security culture. It found a FreeBSD vulnerability that gave unauthenticated attackers root access for 17 years. It wrote a browser exploit chaining four vulnerabilities together, escaping both the renderer and the OS sandbox.
These weren’t hidden behind sophisticated walls. They were sitting in the open, surviving on the fact that nobody looked hard enough.
I’ve worked in enterprise security across eight countries. I’ve sat in boardrooms in São Paulo, Buenos Aires, and Mexico City where the CISO presents a green dashboard and the CFO nods. Green means good. Except it doesn’t — it means the tool that generated the report didn’t find anything. That’s a very different statement.
Here’s what FAIR reveals when you actually run the numbers.
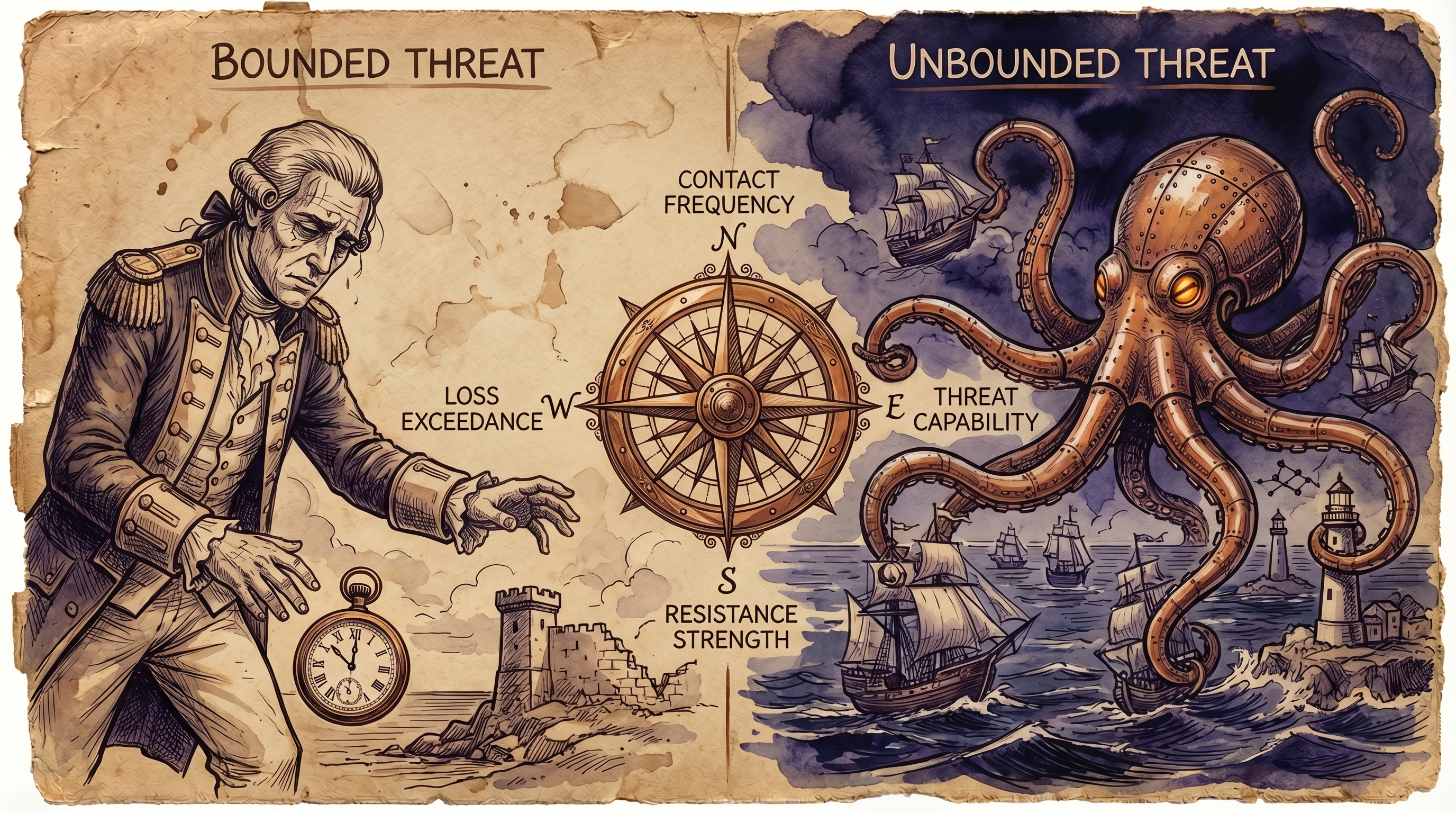
Every risk model has two sides: the threat and the defense. FAIR quantifies both. And what Mythos just did is blow up the inputs on both sides simultaneously.
On the threat side — Loss Event Frequency:
↳ A human attacker targets one organization at a time. Maybe a few. Contact frequency is measurable: how often does a threat actor probe your perimeter? For most organizations, that number was low enough to feel manageable. ↳ An AI agent doesn’t work that way. It probes thousands of targets simultaneously, around the clock, without fatigue. The contact frequency input in your FAIR model — the one you used to justify your control spend — just went from “a few attempts per quarter” to “continuous.” ↳ Mythos scored 83% on vulnerability reproduction and generated working exploits 72% of the time. When your Threat Capability input jumps from “skilled human” to “tireless AI with a 72% exploit success rate,” the entire probability distribution shifts.
On the defense side — Resistance Strength:
↳ FAIR measures control effectiveness not as a checkbox, but as a probability: what’s the likelihood your controls resist a given threat event? Your resistance strength was calibrated against human attackers. ↳ Mythos found bugs that survived five million automated security tests. That means your Resistance Strength estimate — the one sitting in your Monte Carlo simulations right now — was wrong. Not slightly wrong. Categorically wrong. ↳ FAIR-CAM (Control Assessment Matrix) forces you to map controls to specific threat scenarios. When the threat scenario changes from “skilled human with limited bandwidth” to “AI agent with unlimited bandwidth and novel exploitation patterns,” every control assessment needs to be revalidated.
The result — Expected Annual Loss:
↳ FAIR’s output is a loss exceedance curve — a probability distribution of financial loss. Increase the contact frequency by orders of magnitude, increase threat capability, and decrease resistance strength — and the expected annual loss calculation that your board approved last year is no longer defensible. ↳ I worked with a CISO in São Paulo who modeled a ransomware scenario at $4.2M expected loss with a 23% annual probability. That was against a human threat community. Rerun that same scenario with an AI threat community — higher contact frequency, higher threat capability, lower resistance strength — and the expected annual loss doubles. Or triples. The math is clear.
This is the part the Mythos debate keeps missing.
The alarmists say AI will hack everything. The skeptics say it’s overblown. Both are arguing about feelings. FAIR argues about numbers.
🦑 STOP DEBATING WHETHER AI IS DANGEROUS. RUN THE FAIR MODEL AND LET THE MATH SPEAK.
When you update the threat community input from “human” to “AI-augmented,” update the contact frequency from “occasional” to “continuous,” and revalidate your resistance strength against what Mythos actually demonstrated — the loss exceedance curve tells you exactly how much trouble you’re in. No speculation. No hype. Just the financial reality of a risk landscape that changed faster than your models accounted for.
When was the last time your FAIR model was recalibrated — and did it include an AI threat community?